Simple data visualisations have become key to communicating about the COVID-19 pandemic, but we know little about their impact
This article is part of a series of articles exploring the COVID-19 coronavirus pandemic from a knowledge management perspective.
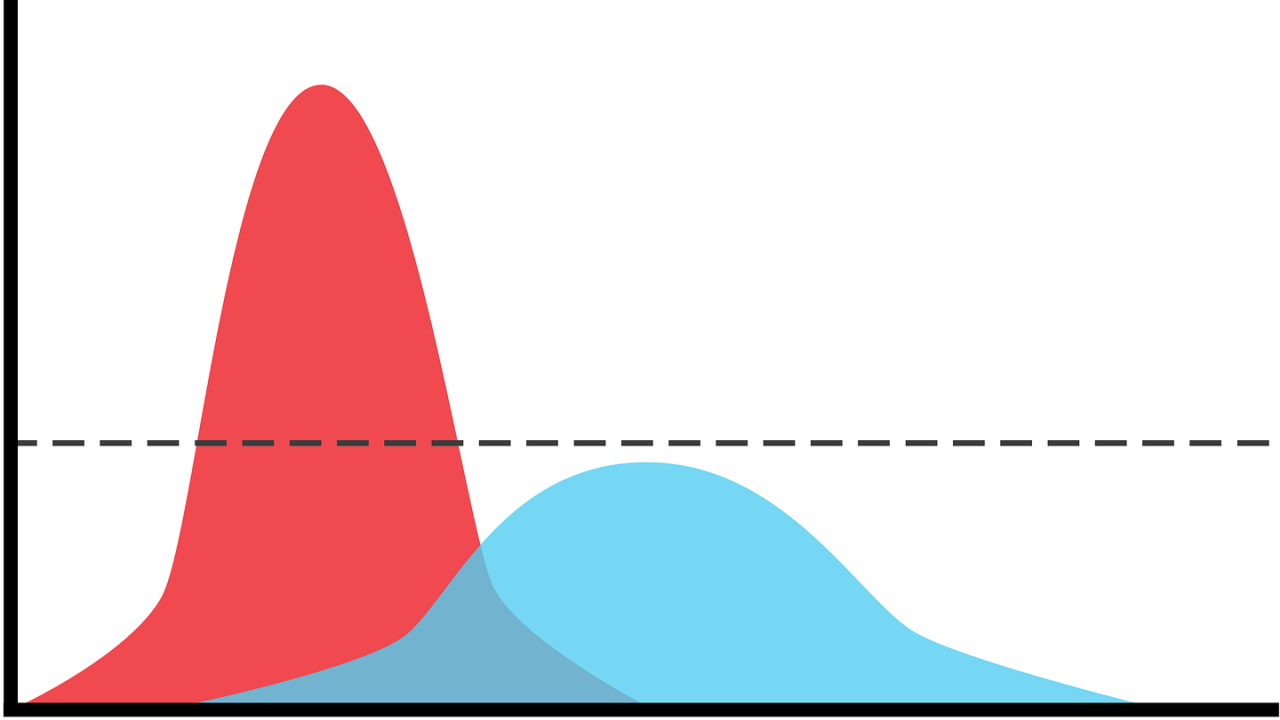
If you had mentioned ‘flattening the curve’ in 2019, chances are you would have been met with a blank stare. However, almost halfway through 2020, the language of data visualisation has become commonplace, and data visualisations are widely used to communicate about the pandemic to the public. However, as Helen Kennedy observes, their power to influence the public is still little understood.
There have never been so many line charts, bar charts and choropleth maps occupying the news, as simple data visualisations have become key to communicating vital information about the coronavirus pandemic to the public. Whilst these terms might not be familiar to all, the visualisations themselves certainly are.
One line chart has even become famous, entering into the everyday vocabulary of the pandemic. I’m referring to the ‘flatten the curve’ line chart explaining the need to slow down the spread of coronavirus in order not to overwhelm healthcare services. Notably, a New York Times article led with said line chart, an unusual move in news journalism, which more frequently leads with a human interest visual like a photograph and provides data in charts and graphs below the line. Variations of the flatten the curve line chart have since abounded, so much that visualisation designer Andy Kirk joked: we need to ‘flatten the curve of new versions of the flatten the curve chart’.

Other coronavirus data visualisations also proliferate. The BBC’s ‘visual guide to the pandemic‘ includes bar charts, interactive maps and line charts showing change over time. Elsewhere, the Financial Times is offering free content incorporating more challenging chart types, like stream graphs and stacked bar charts. The New York Times has been mapping the spread of the virus from its early days, changing what it maps and how it maps as the pandemic unfolds. Worldometers visualises real-time data about the virus, and individual data visualisers are also taking it upon themselves to represent virus data, such as David McCandless’s coronavirus datapack at Information Is Beautiful.
At this time of massive global crisis, it feels almost trivial to write about visual representations of data, but they play a significant role, and the public’s ability to make sense of them has never been more important. Proponents argue that visualisations promote greater understanding of data by making them accessible and transparent, or that, through visualisation, it is possible to ‘do good with data’, the trademarked tagline of US-based visualisation agency Periscopic.
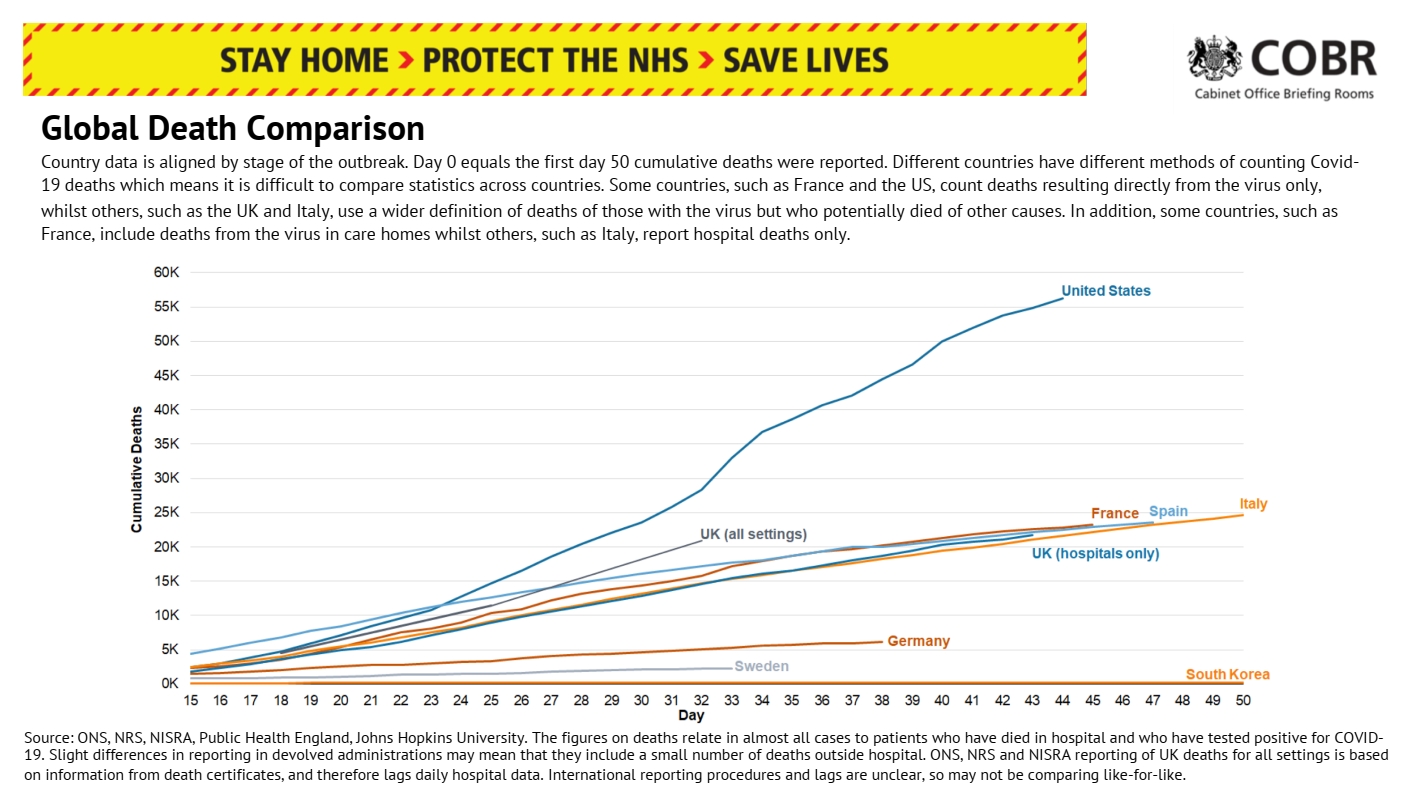
However, the benefits of data visualisation are only half the story. Some argue that data visualisations can do ideological work, privileging certain views of the world and hiding others, or perpetuating existing power relations. Visualisations are not neutral windows onto data; rather, they are the result of ‘judgement, discernment and choice’. On 29th April, for example, the UK government decided to start press pack line graphs of global death comparisons on the day each country recorded its 2000th death, where these graphs had previously started on the day that the 50th death was recorded. This decision obscured the exponential rise in UK deaths compared to other countries. Moving goalposts, as commentators noted on Twitter.

The data on which visualisations are based are also not neutral. Human decisions influence and shape data, as well as their visual representation. Data are never ‘raw’: the very concept of raw data, as Geoffrey Bowker put it, is an oxymoron. Not surprisingly then, the data on which coronavirus maps, charts and dashboards are based are fiercely contested. Data are hard to gather – counting is difficult – but they are also political. There is widespread debate about what data is known but not shared, and who is included and excluded in data about death rates. The Open Data Institute’s Jeni Tennison calls for more openness about data in order to tackle the crisis in the UK, author Cathy O’Neil gives us 10 reasons to doubt coronavirus data, and Bonnie Kristian suggests that coronavirus data visualisation is at best a ‘distorted little sketch.’
What constitute ‘good’ and ‘bad’ data practices is subject to debate, and the topic takes on new dimensions in times of crisis. Forms of data sharing that seemed impossible last month, such as the sharing of health data with supermarkets, are increasingly normal. Notions of public interest, ethics and justice become ever more embattled at times like these, in relation to data and their visual representation as well as in other realms.
Thinking critically about these issues is an important skill for making sense of the data visualisations that are currently circulating. Research that I undertook with others in 2015 suggested that people lacked confidence in their own ‘graphicacy’, or the combination of maths, visual literacy, language, computing and critical thinking skills that are needed to make sense of graphs and charts. But since that research was undertaken, data visualisations have become more commonplace, especially in the simple and standardised formats of bar charts and line charts that proliferate today and that were not the subject of that early research. Designers believe that the circulation of such visualisations on social media make people both too naïve and too skeptical about their truthfulness. But this is speculation: we need to know more about the actual role that these ‘generic visuals’ play in making knowledge, engagement and action possible, and how social inequalities limit these possibilities for certain groups.
![]()
It’s possible, of course, that non-standardised visualisations about coronavirus are more effective at communicating data than simple bar and line charts. In Data Visualization in Society (a book I co-edited with Martin Engebretsen), Jill Simpson draws on her experience of producing a hand drawn data visualisation about her obsessive compulsive disorder to explore how hand drawing communicates a sense of intimacy, authenticity and honesty. Hand drawing evokes emotions, she argues, an important element in data visualisation, as my early research revealed. For me, some of the most effective and affecting coronavirus data visualisations are the hand-drawings of data journalist Mona Chalabi and the cartoon-like animations of microbiologist Siouxsie Wiles and illustrator Toby Morris. These have shown, amongst other things, how the virus spreads more quickly in densely populated areas, how social distancing works, who has the privilege of being able to work from home, and the ways in which the virus is disproportionately affecting black Americans. They deploy the suggested qualities of the hand-drawn to reveal the politics of the pandemic.
As generic visuals like bar and line charts increasingly populate the news and social media, we need more understanding of their social role. Do they bring people together around shared interests and concerns, activate them to care (or not) about issues, make possible (or not) various forms of engagement, facilitate or inhibit the spread of disinformation? For governments and researchers looking to communicate public health information, finding out how simple data visualisations influence the public is now more pressing than ever.
Data Visualization in Society is available to read open access here. The book was launched online on Wednesday 6th May.
Generic visuals in the news is a research project funded by the AHRC which will commence in September 2020.
Biography
 |
Helen Kennedy is Professor of Digital Society at the University of Sheffield. Over 20+ years, she has researched how digital developments are experienced by ’ordinary people’ and how these experiences can inform the work of digital media practitioners. She is currently interested in the datafication of everyday life. She is researching public attitudes to data mining and related issues such as trust in data, data and inequality and what ‘good’ data practice might look like. She is also interested in the role of visual representations of data in everyday life. |
Article source: LSE Impact of Social Sciences Blog, CC BY 3.0. Note: This article gives the views of the author, and not the position of the LSE Impact Blog, nor of the London School of Economics.
Header image source: Markéta Machová on Pixabay, Public Domain.



